 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
题目
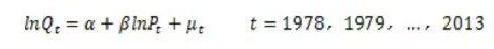
由于我国的人均食品需求量是逐年上升的,食品价格指数也是逐年上升的,所以估计该模型得到的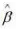 为正。于是得到结论:需求法则不适合于我国。试以该问题为例,分别从经济学、逻辑学和统计学三方面理论出发,说明为什么建立计量经济学总体回归模型必须遵循“从一般到简单”的原则。
为正。于是得到结论:需求法则不适合于我国。试以该问题为例,分别从经济学、逻辑学和统计学三方面理论出发,说明为什么建立计量经济学总体回归模型必须遵循“从一般到简单”的原则。
 更多“某人以我国人均食品需求量Ǫ为被解释变量,以食品价格指数P为解释变量,以1978~2013年的数据为样”相关的问题
更多“某人以我国人均食品需求量Ǫ为被解释变量,以食品价格指数P为解释变量,以1978~2013年的数据为样”相关的问题
第1题
以企业研发支出(R&D)占销售额的比重为被解释变量Y,以企业销售额X1与利润占销售额的比重X2为解释变量,一个容量为32的样本企业的估计结果如下:
Y=0.472+0.32logX1+0.05X2
(1.37) (0.22) (0. 046)
R2=0.099
其中括号中为系数估计值的标准差。
第2题
A.解释变量和被解释变量都是随机变量
B. 解释变量为非随机变量,被解释变量为随机变量
C. 解释变量和被解释变量都为非随机变量
D. 解释变量为随机变量,被解释变量为非随机变量
第3题
A.解释变量和被解释变量都是随机变量
B.解释变量为非随机变量,被解释变量为随机变量
C.解释变量和被解释变量都为非随机变量
D.解释变量为随机变量,被解释变量为非随机变量
第4题
A.解释变量和被解释变量都是随机变量
B.解释变量为非随机变量,被解释变量为随机变量
C.解释变量和被解释变量都为非随机变量
D.解释变量为随机变量,被解释变量为非随机变量
第5题
A、解释变量为随机变量,被解释变量为非随机变量
B、解释变量为非随机变量,被解释变量为随机变量
C、解释变量和被解释变量都为非随机变量
D、解释变量和被解释变量都是随机变量
第6题
A.解释变量和被解释变量都是随机变量
B.解释变量为非随机变量,被解释变量为随机变量
C.解释变量和被解释变量都为非随机变量
D.解释变量为随机变量,被解释变量为非随机变量
第7题
A.解释变量和被解释变量都是随机变量
B.解释变量为非随机变量,被解释变量为随机变量
C.解释变量和被解释变量都为非随机变量
D.解释变量为随机变量,被解释变量为非随机变量
第9题
某一截面数据计量经济学模型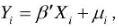 被解释变量服从正态分布,其样本观测值为Y1,Y2....,Yn其中Y1,Y2,Y3取相同的值a,其他观测值均大于a。分别将该组样本看作未受限制的随机抽取样本、以a为截断点的选择性样本、以a为归并点的选择性样本,分别采用最大似然法估计模型。
被解释变量服从正态分布,其样本观测值为Y1,Y2....,Yn其中Y1,Y2,Y3取相同的值a,其他观测值均大于a。分别将该组样本看作未受限制的随机抽取样本、以a为截断点的选择性样本、以a为归并点的选择性样本,分别采用最大似然法估计模型。
(1)写出3种情况下的对数似然函数表达式。
(2)比较3种情况下对数似然函数值的大小,并加以简单证明。
第11题
有人根据美国1961年第一季度至1977年第二季度的季度数据,得到了如下的咖啡需求函数的回归方程:
lnQ?t
(-2.14) (1.23) (0.55)
0.01T-0.10D1t-0.16D2t-0.01D3t
(3.36)(-3.74) (-6.03) (-0.37)
R2=0.80
其中,Q为人均咖啡消费量(单位:磅),P为咖啡的价格(以1967年价格为不变价格),P'为茶的价格(1/4磅,以1967年价格为不变价格),T为时间趋势变量(1961年第一季度为1……1977年第二季度为66);

回答下列问题:
(1) 模型中P、I和P?系数的经济含义是什么?
(2) 咖啡的价格需求是否很有弹性?
(3) 咖啡和茶是互补品还是替代品?
(4) 如何解释时间变量T的系数?
(5) 如何解释模型中虚拟变量的作用?
(6) 哪一个虚拟变量在统计上是显著的(0.05)?
(7) 咖啡的需求是否存在季节效应?
 相关内容
相关内容

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“赏学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!
































