 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
题目

 更多“在下面利用给定的样本数据得到的散点图中,X、Y分别为解释变量和被解释变量。问:各图中随机误差项的”相关的问题
更多“在下面利用给定的样本数据得到的散点图中,X、Y分别为解释变量和被解释变量。问:各图中随机误差项的”相关的问题
第2题
A.JDA特征转化时,降维方法中的数据重构选择PCA来进行
B.通过PCA得到k 维特征表示后,为了减小边缘分布差异,引入最大均值差异MMD,旨在k维嵌入中计算源域数据和目标域数据样本均值之间的距离
C.JDA中,目标域中没有标签数据,不能直接建模,需利用类条件分布来近似,因此可以利用在源域数据上训练得到的基分类器应用到目标域数据,得到目标域数据的伪标签
D.在JDA中,我们的目标是同时最小化域间边缘分布和条件分布的差异
第3题
第4题
第6题
A.①②③④
B.①②④③
C.②①③④
D.②①④③
第7题
使用PNTSPRD.RAW中的数据。
(i)变量sprdcvr是一个二值变量,若在大学篮球比赛中实际分数差距超过拉斯维加斯让分,则此变量取值1。sprdcvr的期望值(比方说u)表示在一场随机抽取的比赛中分差超过让分的概率。在10%的显著性水平上相对于H1:μ≠0.5检验H0:μ=0.5,并讨论你的结果。(提示:将sprdcvr只对一个截距项进行回归便得到一个r统计量,利用这个统计量很容易完成。)
(ii)553个样本中有多少场比赛是在中立场地进行的?
(iii)估计线性概率模型
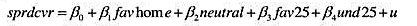
并以通常的形式报告结论。(报告通常的标准误和异方差-稳健的标准误。)哪个变量在实际上和统计上都是最显著的?
(iv)解释为什么在原假设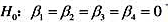 下,模型中不存在异方差性。
下,模型中不存在异方差性。
(v)利用通常的F统计量检验第(iv)部分的原假设,你得到了什么结论?
(vi)给定上述分析,你会不会认为,利用赛前可利用的信息,有可能系统地预测拉斯维加斯让分能否实现?
 相关内容
相关内容

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“赏学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































