 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
题目
本题使用JTRAIN.RAW中的数据。
(i)考虑简单回归模型
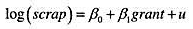
其中,scrap表示企业的废品率,grant表示是否得到工作培训津贴的一个虚拟变量。你能想到u中的无法观测因素可能会与grant相关的原因吗?
(ii)利用1988年的数据估计这个简单的回归模型。(你应该有54个观测。)得到工作培训津贴显著地降低了企业的废品率吗?
(iii)现在增加一个解释变量log(scrap87)。这将如何改变grant的估计影响?解释grant的系数。相对于单侧备择假设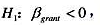 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?
(iv)相对双侧备择假设,检验log(scrapg)的参数为1的虚拟假设。报告检验的P值。
(v)利用异方差-稳健标准误,重复第(iii)步和第(iv)步,并简要讨论任何明显的差异。
 更多“本题使用JTRAIN.RAW中的数据。 (i)考虑简单回归模型 其中,scrap表示企业的废品率,grant表示是”相关的问题
更多“本题使用JTRAIN.RAW中的数据。 (i)考虑简单回归模型 其中,scrap表示企业的废品率,grant表示是”相关的问题
第1题
本题使用WAGE2.RAW中的数据。一般地,保证如下所有回归都含有截距。
(i)将IQ对educ进行简单回归,并得到斜率系数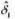

第2题
(x)=x2或g(x)=log(1+x2) 。定义zi=g(xi)定义一个斜率估计量为
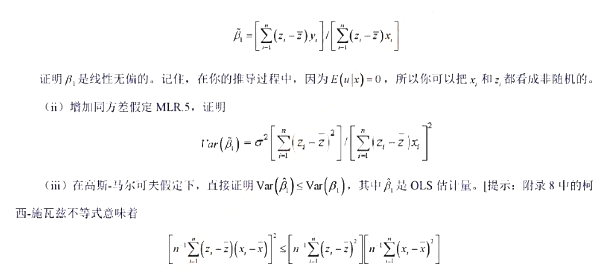
第3题
本题利用JTRAIN.RAW来判断工作培训资助对每位雇员的平均培训小时数的影响。三年的基本模型为
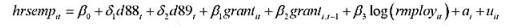
(i)利用一阶差分估计这个方程。估计中使用了多少个企业?如果每个企业都有这三个时期所有变量的数据(特别是hrsemp的数据) , 那么, 总共将使用多少观测?
(ii)解释grant的系数并评论其显著性。
(iii)grant,是不显著的, 这让你感到意外吗?请加以解释。
(iv)平均而言,越大的企业对其员工的培训是越多还是越少呢?在培训上的差异有多大呢?
第6题
本题利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型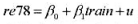 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re 78-re 75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train 78-train75, 那么,由于train75=0,所以ctran=train78。)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
第7题
(i)为了研究垃圾焚化炉的位置对住房价格的影响,考虑简单回归模型
log(price)=β0+β1log(dist)+u
其中,price为住房的美元价格,dst为从住房到焚化炉的距离,以英尺为单位。谨慎地解释这个方程,如果焚化炉的出现会使住房价格下降,你预期到的符号是什么?估计这个方程,并解释你的结论。
(ii)在第(i)部分的简单回归模型中增加变量log(intst),log(area),log(land),
rooms,baths和age,其中intst表示从家到州际高速公路的距离,area表示住房的平方英尺数,land表示占地的平方英尺数,rooms表示总的房间数,baths表示总的卫生间数,age表示住房的年数。现在,你对焚化炉的影响有什么结论?解释为什么第(i)部分和第(ii)部分给出相互矛盾的结论。
(iii)向第(ii)部分的模型中添加[log(dist)]2,结果会怎么样?你对函数形式的重要性有什么结论?
(iv)当你向第(ii)部分的模型中添加[log(dist)]2时,它是否显著?
第8题
本题使用GPA2.RAW中的数据。
(i)考虑方程
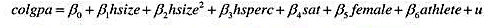
其中,colgpa表示累积的大学GPA,hsize表示高中毕业年级以百人计的规模,hsperc表示在毕业年级中学术排名的百分位,sat表示SAT综合分数,female是一个二值变量,而athlete也是一个运动员取值1的二值变量。你对这个方程中的系数有何预期?哪些你没有把握?
(ii)估计第(i)部分中的方程,并以通常的形式报告结果。估计运动员和非运动员之间GPA的差异是多少?它是统计显著的吗?
(ii)从模型中去掉sat并重新估计这个方程。现在,作为运动员的估计影响是多大?讨论为什么这个估计值不同于第(ii)部分的结论。
(iv)在第(i)部分的模型中,容许作为运动员的影响会因性别不同而不同。检验如下原假设:在其他条件不变的情况下,女生是否是运动员没有差别。
(v)sat对colgpa的影响会因性别不同而不同吗?讲出你的根据。
第9题
利用MEAP00 O1中的数据回答本题。
(i)使用OLS估计模型
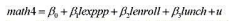
并用通常的格式报告你的结论。在5%的显著性水平上,每个解释变量都是统计显著的吗?
(ii)求出第(i) 部分中回归的拟合值。拟合值的取值范围是多少?它与math4的实际数据取值范围相比如何?
(iii)求出第(i)部分中回归的残差。哪类学校具有最大的(正)残差?对这个残差给予解释。
(iv)在方程中增加所有解释变量的平方项,检验它们的联合显著性。你会把它们放到模型中吗?
(v)回到第(i)部分中的模型,将因变量和每个解释变量都除以各自的样本标准差,并重新进行回归。(除非你还将每个变量分别减去了各自的均值,否则还应该包括一个截距项。)以标准差为单位,哪个解释变量对数学考试通过率具有最大的影响?
 相关内容
相关内容

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“赏学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

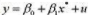 ,其中我们对
,其中我们对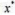 有m种度量,并记为
有m种度量,并记为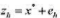 ,
,






























