 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
题目
本题利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型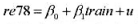 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re 78-re 75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train 78-train75, 那么,由于train75=0,所以ctran=train78。)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
 更多“本题利用JTRAIN3.RAW中的数据。(i)估计简单回归模型并用常用格式报告结论。基于这个回归,1976年”相关的问题
更多“本题利用JTRAIN3.RAW中的数据。(i)估计简单回归模型并用常用格式报告结论。基于这个回归,1976年”相关的问题
第1题
利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型re78=β0+β1train+u,并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re78-re75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train78-train75,那么,由于train75=0,所以ctrain=train78.)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
第2题
利用MEAP00 O1中的数据回答本题。
(i)使用OLS估计模型
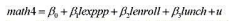
并用通常的格式报告你的结论。在5%的显著性水平上,每个解释变量都是统计显著的吗?
(ii)求出第(i) 部分中回归的拟合值。拟合值的取值范围是多少?它与math4的实际数据取值范围相比如何?
(iii)求出第(i)部分中回归的残差。哪类学校具有最大的(正)残差?对这个残差给予解释。
(iv)在方程中增加所有解释变量的平方项,检验它们的联合显著性。你会把它们放到模型中吗?
(v)回到第(i)部分中的模型,将因变量和每个解释变量都除以各自的样本标准差,并重新进行回归。(除非你还将每个变量分别减去了各自的均值,否则还应该包括一个截距项。)以标准差为单位,哪个解释变量对数学考试通过率具有最大的影响?
第3题
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。
(i)从加速数模型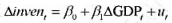 中求出OLS残差,并用
中求出OLS残差,并用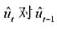 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
(ii)用PW估计这个加速数模型,并将β1的估计值与OLS估计值进行比较。你为什么预期它们很相似?
第4题
本题利用HPRICE1.RAW中的数据。
(i)估计模型
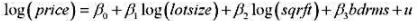
并以通常的OLS格式报告结论。
(ii)当lotsize=20000,scrft=2500和bdrms=4时,求出log(price) 的预测值。利用6.4节中的方法,在同样的解释变量值的情况下,求出price的预测值。
(iii)就解释price中的变异而言,决定你是偏好第(i)部分中的模型,还是偏好模型
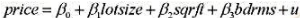
第5题
利用HPRICE1.RAW中的数据。
(i)估计模型
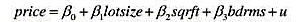
并按通常的格式报告你的结果,包括回归标准误。当我们代入lotsize=10000,sqrft=2300和bdrms=4时,求出预测价格,将这个价格四舍五入到美元。
(ii)做一个回归,使你能得到第(i)部分中预测值的一个95%的置信区间。注意,由于四舍五入的误差,你的预测将多少有些不同。
(iii)令price0为具有第(i)部分和第(ii)部分所述特征的住房的未知未来售价。求出price0的一个95%的置信区间,并对这个置信区间的宽度进行评论。
第6题
本题使用HTV.RAW中的数据。
(i)基于整个样木, 利用解释变量educ、abil、exper、nc、west、south和urban, 利用OLS估计log(wage)的一个模型。报告教育的估计回报及其标准误。
(ii)现在, 仅利用educ<16的人群来估计第(i) 部分中的方程。样本损失了多大的比例?现在, 多读一年书的估计回报是多少?它与第(i)部分中的结果相比如何?
(iii)现在, 去掉所有wage≥20的观测, 于是, 样本中剩下每个人每小时工资都不足20美元。做第(i) 部分中的回归, 并评论educ的系数。(由于正常的断尾回归模型都假定y是连续的, 所以理论上我们去掉wage≥20还是去掉wage>20都无所谓。但在这个应用研究中, 由于有些人正好每个小时挣20美元, 所以二者略有差异。)
(iv)利用第(ii) 部分中的样本, 应用断尾回归[上断点为log(20) ] .假定第(i) 部分中得到的估计值是一致的,这个断尾回归能够重新得到整个总体中的教育回报估计值吗?
第7题
本题使用JTRAIN.RAW中的数据。
(i)考虑简单回归模型
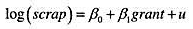
其中,scrap表示企业的废品率,grant表示是否得到工作培训津贴的一个虚拟变量。你能想到u中的无法观测因素可能会与grant相关的原因吗?
(ii)利用1988年的数据估计这个简单的回归模型。(你应该有54个观测。)得到工作培训津贴显著地降低了企业的废品率吗?
(iii)现在增加一个解释变量log(scrap87)。这将如何改变grant的估计影响?解释grant的系数。相对于单侧备择假设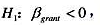 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?
(iv)相对双侧备择假设,检验log(scrapg)的参数为1的虚拟假设。报告检验的P值。
(v)利用异方差-稳健标准误,重复第(iii)步和第(iv)步,并简要讨论任何明显的差异。
第8题
(i)在数据集JTRAIN2.RAW中,男人参加工作培训的比例是多大?在JTRAIN3.RAW中的比例又是多大?你认为为什么存在这么大的差距?
(ii)利用JTRAIN2.RAW,做re78对train的简单回归。参与工作培训对真实工资的估计影响有多大?
(ii)现在,在第(ii)部分的回归中增加控制变量re74,re75,educ,age,black和hisp。工作培训对re78的估计影响变化大吗?何以至此?(提示:记得这些都是实验数据。)
(iv)利用JTRAIN3.RAW中的数据做第(ii)部分和第(iii)部分的回归,只报告train的估计系数及其:统计量。现在,控制额外因素的影响如何?为什么?
(v)定义avgre=(re74+re75)/2。求这两个数据集中的样本均值、标准差、最小值和最大值。这些数据集代表了1978年同样的总体吗?
(vi)在数据集JTRAIN2.RAW中,几乎96%的男性的avgre低于10000美元。只利用这些男性的数据,做re78对train,re74,re75,educ,age,black和hisp的回归,并报告培训估计值及其:统计量。对JTRAIN3.RAW
也只利用avgre ≤10的男性做同样的回归。就这个低收入男性子样本而言,实验数据集和非实验数据集估计的培训效应有何差别?
(vii)现在,只针对1974年和1975年失业的男性,利用每个数据集做re78对train的简单回归。培训的估计值又有何差别?
(viii)利用你前面的回归结果,试讨论在比较实验估计值和非实验估计值的背后,拥有可比较总体的潜在重要性。
第9题
(i)利用WAGEPRC.RAW中的数据,估计第11章习题5中的分布滞后模型。用回归教材(12.14)来检验AR(1)序列相关。
(ii)用迭代的科克伦-奥卡特方法重新估计这个模型。长期倾向的新估计值是多少?
(iii)用迭代C0求出LRP的标准误。(这要求你估计一个修正方程。)判断LRP估计值在5%的水平上是否统计显著异于1?
第10题
关。
(ii)用迭代的科克伦-奥卡特方法重新估计这个模型。长期倾向的新估计值是多少?
(iii)用迭代C0求出LRP的标准误。(这要求你估计一个修正方程。) 判断LRP估计值在5%的水平上是否统计显著异于1?
 相关内容
相关内容

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“赏学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































