重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
题目
给定由两次运行K均值产生的两个不同的簇集,误差的平方和最大的那个应该被视为较优。()
 更多“给定由两次运行K均值产生的两个不同的簇集,误差的平方和最大的那个应该被视为较优。()”相关的问题
更多“给定由两次运行K均值产生的两个不同的簇集,误差的平方和最大的那个应该被视为较优。()”相关的问题
第1题
A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象
B.K均值使用簇的基本原型概念,而DBSCAN使用基于密度的概念
C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇
D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但DBSCAN会合并有重叠的簇
第2题
A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象
B.K均值使用簇的基于原型的概念,而DBSCAN使用基于密度的概念
C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇
D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇
E.K均值和DBSCAN的最初版本都是针对欧几里得数据设计的,但是它们都被扩展,以便处理其他类型的数据
第8题
A.解决聚类问题的一种经典算法,简单、快速
B.对处理大数据集,该算法是相对可伸缩和高效率的
C.当结果簇是密集的,它的效果较好
D.必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果
 相关内容
相关内容

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“赏学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

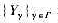 和
和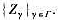 证明:
证明: