 重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
重要提示:
请勿将账号共享给其他人使用,违者账号将被封禁!
题目
利用VOTE1.RAW中的数据。
(i)考虑一个含有竞选支出交互项的模型
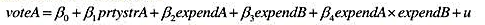
保持prtystrA和expendA不变,expendB对voteA的偏效应是什么?expendA对voteA的偏效应是什么?β4的预期符号明显吗?
(ii)估计第(i)部分中的方程,并以通常的格式报告结果。交互项是统计显著的吗?
(ii)求样本中expendA的均值。固定expendA为300(300000美元)。候选人B另外支出100000美元对voteA的估计影响是什么?这个影响很大吗?
(iv)现在固定expendB为100。AexpendA=100对voteA的估计影响是什么?这讲得通吗?
(v)现在估计一个用候选人A的支出占竞选总支出的百分比shareA取代交互作用项的模型。同时保持expendA和expendB不变而改变shareA,这讲得通吗?
(vi)(要求有微积分知识)在第(V)部分的模型中,保持prtystrA和expendA不变,求出expendB对voteA的偏效应。在expendA=300和expendB=0时进行计算,并评论你的结论。
 更多“利用VOTE1.RAW中的数据。 (i)考虑一个含有竞选支出交互项的模型 保持prtystrA和expendA不变,e”相关的问题
更多“利用VOTE1.RAW中的数据。 (i)考虑一个含有竞选支出交互项的模型 保持prtystrA和expendA不变,e”相关的问题
第1题
本题使用VOTEI.RAW中的数据。
(i)估计一个以vote A为因变量并以prtystrA、democA、log(expend A) 和

(ii)现在计算异方差性的布罗施-帕甘检验。使用F统计量的形式并报告P值。
(iii)同样利用F统计量形式计算异方差性的特殊怀特检验。现在异方差性的证据有多强?
第2题
本题利用NBASAL.RAW中的数据。
(i)估计一个线性回归模型,将单场得分与联赛中打球经历和位置(后卫、前锋或中锋)联系起来。包括打球经历的二次项形式,并将中锋作为基组。以通常的形式报告结果。
(ii)在第(i)部分中,你为什么不将所有三个位置虚拟变量包括进来?
(iii)保持经历不变,一个后卫的得分比一个中锋多吗?多多少?这个差异统计显著吗?
(iv)现在,将婚姻状况加入方程。保持位置和经历不变,已婚球员是否更高效(就单场得分来说)?
(v)加入婚姻状况和两个经历变量的交互项。在这个扩展的模型中,是否存在有力的证据表明婚姻状况影响单场得分?
(vi)使用单场助攻次数作为因变量估计(iv)中的模型。与(iv)的结果有明显的差异吗?请讨论。
第3题
(i)利用INJURY.RAW中肯塔基州的数据,从教材(13.12)中去掉afchnge后估计的方程为

交互项的估计值与式(13.12)中的估计值相当接近,这令人吃惊吗?请解释。
(ii)当包含afchnge而去掉highearn后结果是
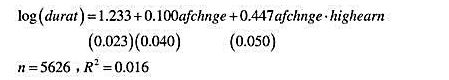
为什么现在交互项的系数远大于教材(13.12)中的系数?[提示:在方程(13.10)中,若β1=0,对处理组和对照组做的假定是什么?]
第4题
在例9.1中,我们narr86在的一个线性模型中增加二次项pcrv2、ptime86²和inc 862。
(i)利用CRIME L RAW中的数据, 在例17.3的泊松回归中同样增加这些项。
(ii)根据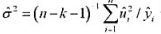 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
(iii)利用第(i)部分和第(ii)部分的结论及教材表17.3,计算这三个平方项联合显著性的准似然比统计量。你得到什么结论?
第5题
考虑一个雇员水平的模型

(iv)讨论第(iii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
 相关内容
相关内容

 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“赏学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!































